TL;DR- We present RealCam, a real-time framework for interactive camera-controlled generative rendering from a single video.
Abstract
Camera-controlled video-to-video (V2V) generation enables dynamic viewpoint synthesis from monocular footage, holding immense potential for interactive filmmaking and live broadcasting. However, existing implicit synthesis methods fundamentally rely on non-causal, full-sequence processing and rigid prefix-style temporal concatenation. This architectural paradigm mandates bidirectional attention, resulting in prohibitive computational latency, quadratic complexity scaling, and inherent incompatibility with real-time streaming or variable-length inputs. To overcome these limitations, we introduce RealCam, a novel autoregressive framework for interactive, real-time camera-controlled V2V generation. We first design a high-fidelity teacher model grounded in a Cross-frame In-context Learning paradigm. By interleaving source and target frames into synchronized contextual pairs, our design inherently enables length-agnostic generalization and naturally facilitates causal adaptation, breaking the rigid prefix bottleneck. We then distill this teacher into a few-step causal student via Self-Forcing with Distribution Matching Distillation, enabling efficient, on-the-fly streaming synthesis. Furthermore, to mitigate severe loop inconsistency in closed-loop trajectories, we propose Loop-Closed Data Augmentation (LoopAug), a novel paradigm that synthesizes globally consistent loop sequences from existing multiview datasets. Extensive experiments demonstrate that RealCam achieves state-of-the-art visual fidelity and temporal consistency while enabling truly interactive camera control with orders-of-magnitude faster inference than existing paradigms.
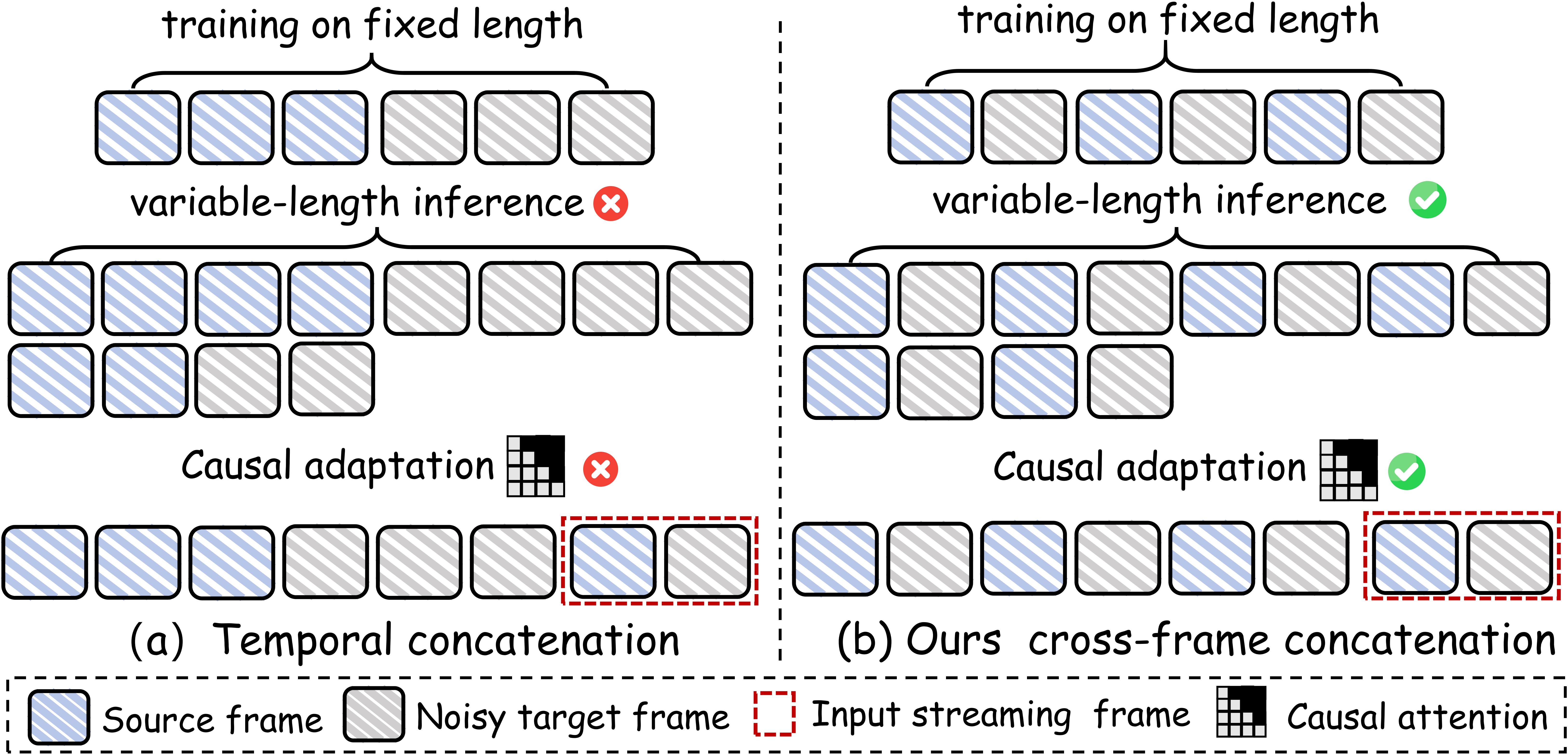
Cross-frame In-context Learning
we employ a structural shift from prefix-style conditioning (temporal concatenation) to synchronous frame-pair processing. Instead of treating
the source video as a long-range prefix, we interleave source and target frames into a unified sequence of contextual
pairs. This cross-frame design provides two decisive advantages:
Causal Compatibility– By processing each frame-pair synchronously, the teacher model can naturally transition to a causal adaptation (e.g.,
replacing bidirectional attention with causal masks) without breaking the conditional dependency, enabling
frame-by-frame generation.
Dynamic Robustness – Our cross-frame paradigm focuses on relative positional relationships rather than absolute sequence length, allowing the
model to generalize to arbitrary video lengths during inference.
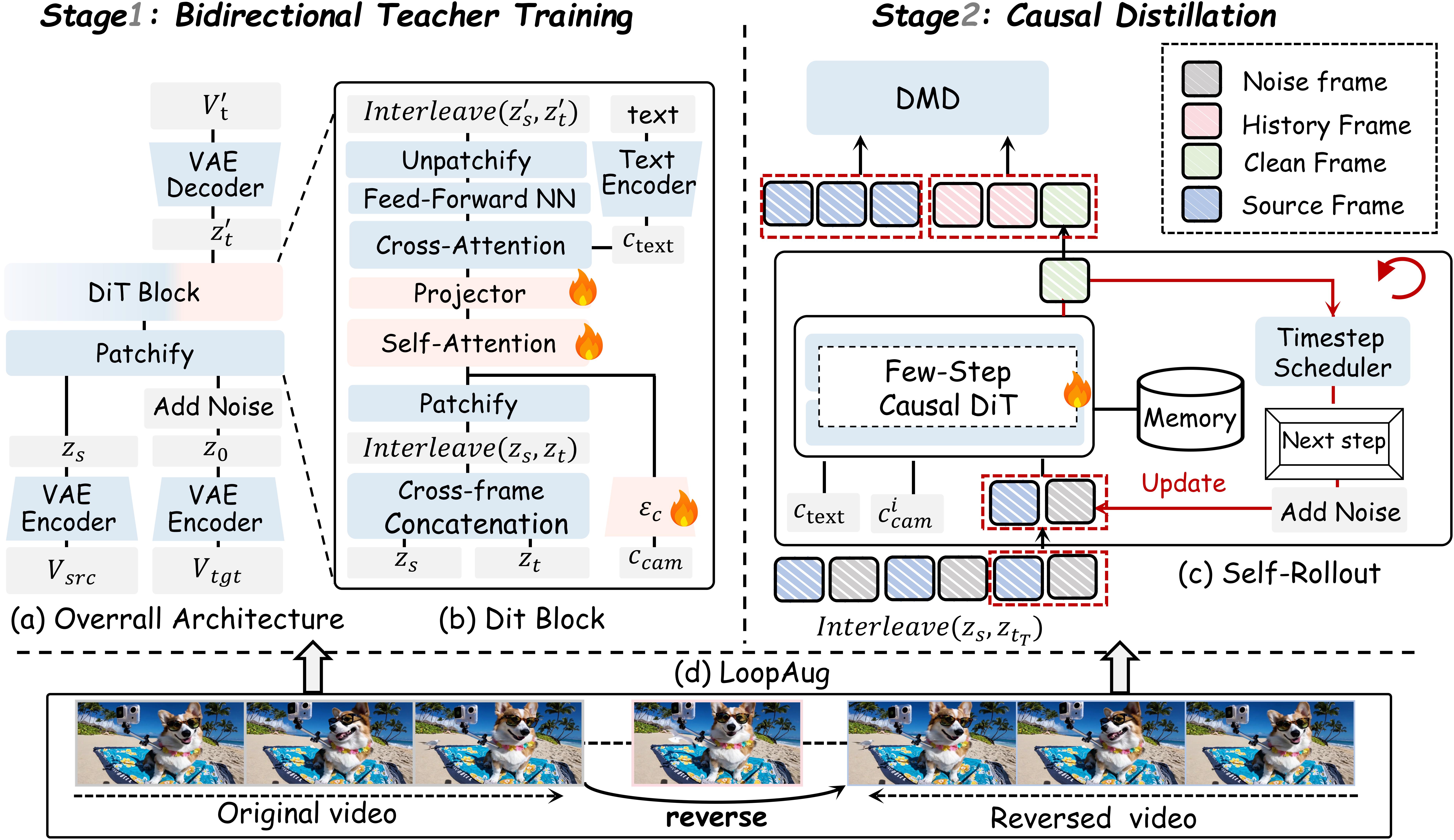
An overview of our proposed RealCam framework
Our method consists of two phase:
Bidirectional Teacher Training via Cross-frame In-context Learning– our core insight is to refactor the video-to-video relationship by interleaving source and target
frames into unified contextual pairs, enabling the model to generalize to arbitrary video lengths and naturally
transition to causal attention.
Causal Distillation with LoopAug – building upon this cross-frame teacher, we distill it into a causal student through self-forcing rollout, augmented with
our proposed Loop-Closed Data Augmentation (LoopAug) to resolve temporal drift in cyclic trajectories.
Experiments
Comparisons with state-of-the-art methods
Ablation on Loop-Closed Data Augmentation(LoopAug).
More results
Reference Videos
Our project page is borrowed from Dynamic Concepts. Thanks for their great work!
BibTeX Citation
@article{xu2026realcam,
title={RealCam: Real-Time Novel-View Video Generation with Interactive Camera Control},
author={Xu, Youcan and Shi, Jiaxin and Wang, Zhen and Song, Wensong and Shao, Feifei and Liang, Chen and Xiao, Jun and
Chen, Long},
journal={arXiv preprint arXiv:2605.06051},
year={2026}
}
[1] Bai, Jianhong, et al. "Recammaster: Camera-controlled generative rendering from a single video." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2025.
[2] Yu, Mark, et al. "Trajectorycrafter: Redirecting camera trajectory for monocular videos via diffusion models." Proceedings of the IEEE/CVF international conference on computer vision. 2025.
[3] Park, Byeongjun, et al. "ReDirector: Creating Any-Length Video Retakes with Rotary Camera Encoding." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2026.